 By Richard Boire
By Richard Boire
In many of the seminars and courses in data mining and data science that I have delivered segmentation is always considered a core topic. But what does it really mean and how should be used in the context of delivering business value?
The first task is always the definition of segmentation, which again is very simple as it is the assignment of records, or in this case customers, into different groups. However, it is how this assignment occurs where the concept of segmentation can comprise several different approaches.
Business rules
1. The simplest approach assignment is based on business rules where there is some pre-determined learning. For example, a marketing analysis might reveal that males are more likely to purchase a certain product than females. In this simple case, we then decide to create segments based on gender.
Profiling
2. Another common form of segmentation is the notion of the profile. In this approach, we are essentially trying to identify look-alike type customers. This form of segmentation attempts to look at potential segments.
For example, one exercise might be to identify those low-value customers who most look like high-value customers. However, one must be careful in creating the profile of potential high-value customers when analyzing the data.
Without really thinking through the data, an analyst will delve into the data and determine that a high-value customer has had essentially high activity with the company, such as high spending and a high number of transactions.
But for the marketer this information is meaningless since they want to look at low-activity customers that look like high-value customers.
In other words, what are the demographics of these customers? Are they, for example, high income, female and young? With the profile comprising demographics, the marketer can act on this information by targeting this segment who are currently low value.
Cluster segmentation
3. But the most common form of segmentation is cluster segmentation, which has been used by businesses for decades.
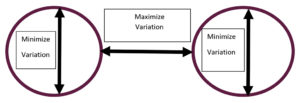
The mathematics behind the cluster segmentation approach is essentially based on variation from the mean. In simplistic terms, the algorithm attempts to identify those variables where the variation or difference between a given variable’s values within that cluster and the variable mean of that cluster is minimized. Yet the variation of these same variables is maximized across or between the cluster group variable means.
See schematic below:
 The earliest form of segmentation used by many businesses were the PRIZM-based geographical clusters (currently 68), which were developed in the 1980s and pioneered by Environics Analytics. These geographical segments were, and continue to be, very useful in identifying unique segments of the Canadian population. Listed in the next column is a sample of four such cluster segments:
The earliest form of segmentation used by many businesses were the PRIZM-based geographical clusters (currently 68), which were developed in the 1980s and pioneered by Environics Analytics. These geographical segments were, and continue to be, very useful in identifying unique segments of the Canadian population. Listed in the next column is a sample of four such cluster segments:
Businesses can use these unique segment insights and tailor their marketing efforts around them. Not only can these segments can be used for targeted marketing efforts, the more important advantage is one of communication as marketers can frame their messaging around unique groups of customers.
Segmentation and the development of customized cluster segments has become very attractive to businesses due to the strategic outcomes of this process.
Traditionally, organizational structure and alignment was product-silo based. Departments and divisions were based on products. During the early days of my career, at Reader’s Digest we had separate departments related to books, magazines and records, while at American Express, the structure was aligned based on card type (personal, gold, platinum) and ancillary products, such as insurance and merchandise.
But in today’s environment, as organizations strive to be more customer-focused, the thinking is that the organizational structure should be more aligned toward unique customer segments. As opposed to managing products and service departments or divisions, organizations are now managing customer segments as a fundamental component of their overall corporate strategy.
Cluster approach limits
Despite the attractiveness of the cluster segment approach and its potential to derive new business strategies, in many cases, this approach is not relevant, given the current data environment.
What do I mean by this? Because of the mathematics involved in clustering, these techniques work best when the data environment is somewhat stable.
For example, assume that we are asked to develop a new segmentation system for loyalty card customers that was launched six months ago. Any marketer would understand that trying to apply any statistical insights of customers from a six-month programme to customers after 12 months is going to be very nebulous. The organization is in heavy acquisition growth mode as it may expect to double its customer base every six months.
Customer characteristics between six months and 12 months are likely to comprise very different behaviours and demographics, implying a very dynamic data environment. The robustness of these tools is severely compromised in a data environment that is changing quite dramatically. Another approach is required.
The value of VBS
Enter the value-based segmentation (VBS) or value-behaviour-based approach. With it, customers are segmented on two dimensions: value and change in behaviour.
Within this first dimension of value our initial task is to identify what the customer value is for that specific company. This involves extensive collaboration amongst the different stakeholders, so that consensus on defining customer value is attained.
With this consensus, the next task is the actual assignment of value to the customer. These customers are then sorted by value into deciles, which look as follows:
From that chart we then see how customer value distributes across all the deciles. The top two deciles represent the high value segment, while deciles 3-6 represent the medium value segment and deciles 7-10 represent the low value segment. Note the negative value in Decile 10 indicates that there is a credit component in that decile, implying that this group of customers represent customers with significant credit losses.
The second dimension of VBS deals with change of behaviour, where we look at how customers are changing over time.
This necessitates that we first determine what is the appropriate purchase window for a given customer regarding this particular product or service. Once this is determined, we then create a window of time whereby we look at purchase behaviour in this pre-purchase period and then look at purchase behaviour in the post-purchase period. Change in behaviour between the pre-purchase period and the post-purchase period then determine the behavioural segments.
For example, the following behavioural segments are as follows:
Reactivators: no activity in the pre-purchase period and activity in the post-purchase period;
Defectors: activity in the pre-purchase period and no activity in the post-purchase period;
Growers: Significant increase in activity in the post-purchase period versus the pre-purchase period;
Decliners: Significant decrease in activity in the post-purchase period versus the pre-purchase period; and
Stables: No significant change in activity between the pre-purchase and post-purchase periods.
At the end of this exercise, we end up producing the following segmentation matrix where segments are classified according to the two dimensions of value and change in behaviour. See below:
The end deliverable is a segmentation system that operates in a very dynamic data environment where customers can be segmented based on value and change in behaviour.
The above discussion reinforces the notion that segmentation is a not one-size-fits-all option. Segmentation approaches will depend on the data environment, business objectives and the balance between the degree of complexity versus speed and simplicity in building the appropriate solution. But whether or not solutions are simple versus complex, customer segmentation is a key requirement for any organization that is in the process of developing “customer experience” type strategies.
Richard Boire is president of Boire Analytics, an organization that is a leader in data analytics with over 30 years in applied analytics solutions across virtually all industry disciplines. He can be reached at boire@boireanalytics.com or for more information, go to: www.boireanalytics.com.
Related Posts



